
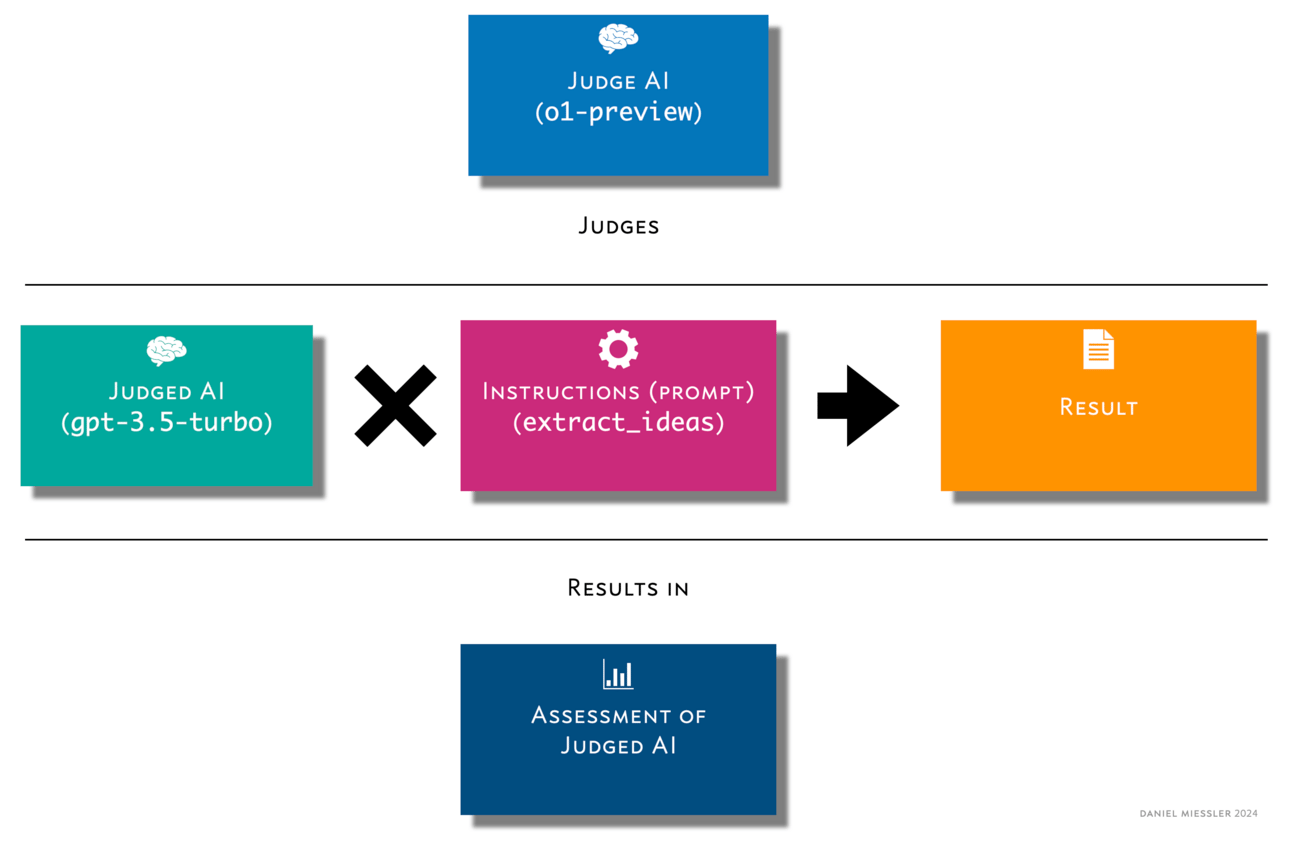

The structure of the rate_ai_result Stitch
Since early 2023 I’ve wanted a system that can assess how well AI does at a
given task.
And when I say “system”, what I really mean is an AI system. Which means I
want an AI system that rates AI systems. There are a bunch of these out
there now, as well as a number of AI output eval frameworks that are
somewhat useful.
But I wanted a simpler architecture that uses high-quality prompting to do
the work. In other words, what could I give a smart, Judging AI as
instructions such that it can evaluate the sophistication of
less smart, to-be-tested
AI? So here’s the structure I used.
A typical result of the assessment
I created a
Fabric
Pattern called rate_ai_result which is used by the smartest
AI available (the Judging AI). In this case, I’m using
o1-preview.
THE PATTERN
Craft a Stitch (piped Patterns working together) that collects all the
components together to send to the Judging AI.
The components are:
a. The input that the first AI will do its work on
b. The
instructions for the first AI on how to perform the task
c. The
output of the AI’s work
Those are then sent to the Judging AI using a single command.
(echo "beginning of content input" ; f -u
https://danielmiessler.com/p/framing-is-everything ; echo "end
ofcontent input"; echo "beginning of AI instructions (prompt)"; cat
~/.config/fabric/patterns/extract_insights/system.md; echo "end of AI
instructions (prompt)" ; echo "beginning of AI output" ; f -u
https://danielmiessler.com/p/framing-is-everything | f -p
extract_insights -m gpt-3.5-turbo ; echo "end of AI output. Now you
should have all three." ) | f -rp rate_ai_result -m
o1-preview-2024-09-12
In this command, we’re pulling the content of a webpage, pulling the
content of the AI instructions (the prompt/Pattern), and then pulling
the results of the AI doing the task using gpt-3.5-turbo.
That is all then sent to the rate_ai_result Pattern using
o1-preview.
The command from Step 4.
rate_ai_result Pattern
The setup is simple enough, but most of the magic is in the rating pattern
itself.
What I’m having it do is think deeply about how to assess the quality of how
the task was done—given the fact that it has the input, the prompt, and the
output—relative to various human levels. Here are the steps within the
Pattern/prompt.
A snippet of the rate_ai_result Pattern (click through for full pattern)
We also told it to rate the quality of the AI’s work across over 16,000
dimensions. We also gave it multiple considerations to use as seed examples
of analysis types (which reminds me a lot of Attention, actually).
Hints to o1 on how to build its own multi-dimensional rating system
This is one of my experimental techniques that I’ve been playing with in my
prompts, and we need to understand that tricks like this could range from
highly effective, to completely useless, to even counter-productive. I
intend to test that more soon using eval frameworks, or wait until the
platforms do it themselves. But if any model so far might be able to use
such trickery, it’s o1.
Anyway, here’s the result that came back: Bachelor’s Level.
GPT 3.5 Turbo got a rating of Bachelor’s Level
After hacking on this for a few hours this weekend I am happy to report
something.
I’ve got this thing predictably scoring the sophistication of various
models on the human scale—across multiple types of task.
In other words, GPT-3.5 is scoring as High School or Bachelor’s
level—predictably—doing
lots of different AI tasks. So,
Threat Modeling
Finding Vulnerabilities
Writing
Summarization
Contract Reviews
Etc.
…while GPT-4o and Opus score way higher—and o1 scores the highest! Again,
across various tasks and multiple runs.
That’s insane.
It means—as kludgy as this first version is—we have a basic system for
judging the “intelligence” of an AI system relative to humans. And I’m
pretty sure I can make this thing way better with just a bit of work.
What’s coolest to me about it is that it’s a framework. When the new best
model comes out, that becomes the judge. And when new models come out we
want to test for particular tasks (like tiny models optimized for a
particular thing), we can just plug them in. Plus we can keep optimizing the
rate_ai_result pattern itself.
Anyway, just wanted to share this so people can attack it, improve it, and
build with it.
Meet Mary — Your Smart AI ICT Teacher for O-Level Secondary Education in Uganda! Welcome…
Journey Through Faith: An Introduction to Senior Three Islamic Religious EducationWelcome, students, to an enriching…
Meet Isha Karungi — Your Smart AI Islamic Studies Teacher for O-Level! Welcome to the…
Having studied Spanish for over 6 years, I knew what dulce de leche meant. Sweet.…
I found kiwis on sale. Five for $1! In the middle of winter. In January.…
An experience. That’s what Ghirardelli is to me. For many years, San Francisco was a…




Leave a Comment